
The testing pyramid introduced by Mike Cohn in his book Succeeding with Agile (2009), originally had only 3 tiers, given it was more than a decade ago we should ask ourselves is that still accurate?
First, let’s take a look at the original pyramid
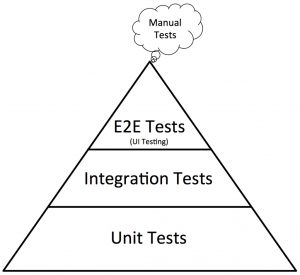
- Unit tests might be written for front-end, back-end, or any other middleware services.
- Integration tests it is a little hard to have a clear line of what integration tests represent, some might say that is component-level testing, and some will tell those types of tests need to be done on API level, for others, it might be working with event distribution services like RabbitMQ and Kafka. So the line is unclear it really depends on the project and what you have in your test strategy. (there is a good article uncovering all those uncertainties, really recommend reading Practical Testing Pyramid)
- E2E (end to end) testing for most people in our industry is test automation over UI using tools like Selenium, Cypress, Playwright, and Puppeteer.
Now let’s touch a little bit on the part where Quality Engineers get involved the most, in the top two. With the development of AI and image recognition services, we can say that there should be an extra tier on top of the pyramid representing visual regression testing.
Visual regression testing is the type of testing where you take snapshot of a page or component and then with help of image recognition services do a visual comparison of the page (component). This type of testing is crucial for client-facing applications. There are lots of services that allow you to do this the most popular Applitools, Percy (paid cloud-based services), and jest-image-snapshot (npm package built AmericaExpress).
Another tier of testing could be placed in between E2E and Integration, let me explain what do I mean by that. Typically your UI tests go over UI components, as long as those components get back the correct data they don’t really care how they got the necessary data back. The same goes for integration tests that normally stop at the API level, so given you have the endpoint it doesn’t really matter how the return data getting consumed by the UI, we gave you what we promised. When those two work together and tools like Cypress let you do that, that is where it gets interesting. Here are a couple of examples I worked on.
I worked on setting up data for my E2E tests where I realized that there are two versions of the same endpoint (let us call it v1 and v2) which have been called on the same page. You would think the v1 would be removed once you transitioned to v2, but that’s not what happened. For some reason, v2 was missing a data field that was represented in v1, so now the application has to make two calls to different versions of the same endpoint to get all the necessary data. If we look at this from UI testing perspective you get your data back, you don’t really know how but all looks good on your side. Then on the API level you test the endpoint and looks good as well because endpoints return the data and it is what is written in API docs. But when you put those two together and look at the implementation that’s where you see that something is wrong.
Another example is the exact same situation I looked at UI and API tests all looks great, but when I looked in between I noticed that the same endpoint was called multiple times on the same page, apparently there was a bug in UI that caused the trouble.
So now if we look at our pyramid it should have more than 3 tiers and as rightfully noticed in the Practical Testing Pyramid article it is a little vague and simplistic. It is a good starting point, but certainly not enough.


