When teams start building AI-powered products, the first optimization question is usually:
“Should we use a cheaper model?”
That’s a good question, but it’s only one piece of a much bigger picture. Every LLM call ultimately costs:
(input tokens × input rate) + (output tokens × output rate)
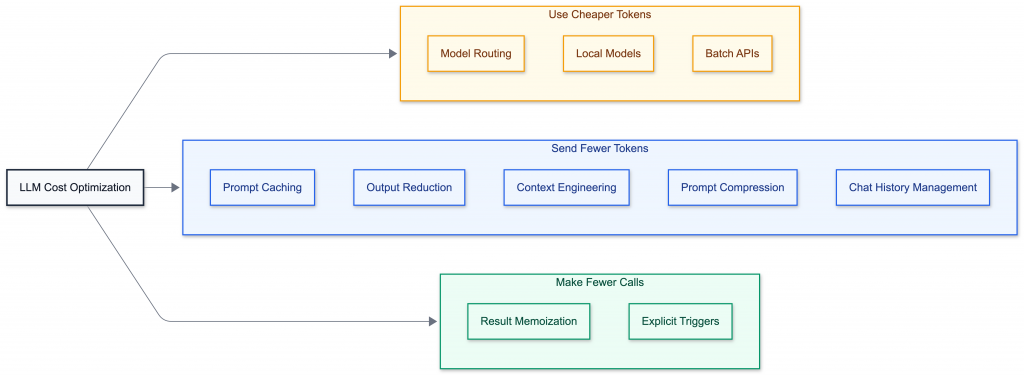
One detail many teams miss: output tokens are often 4–5x more expensive than input tokens. Once you understand that equation, cost optimization becomes much simpler. There are only three ways to reduce LLM spend:
- Use cheaper tokens
- Send fewer tokens
- Make fewer calls
Everything else is just a variation of those three levers.
Lever 1: Use Cheaper Tokens
Model Routing
Model routing is often the highest ROI optimization because it’s easy to implement and usually has little risk. Instead of sending every request to your most capable model, route tasks based on complexity.
Below is an example from an agent I’m currently building. It has several flows, and instead of using the same model across all tasks, I assign models based on task complexity.
const MODEL_BY_TASK = {
analyze: 'claude-haiku-4-5',
chat: 'claude-haiku-4-5',
impact: 'claude-sonnet-4-6',
testPlan: 'claude-sonnet-4-6'
};
Structured extraction, summarization, and conversational follow-ups typically don’t need your most expensive model. Trust-critical reasoning, planning, or complex analysis often does. This simple routing strategy can reduce costs by 3–4x for a large portion of requests while keeping quality intact.
Escalation Routing
The next level is a cascade approach:
- Run a cheap model first.
- Check confidence.
- Escalate only when confidence is low.
Example:
Impact Analysis
└─ Haiku
└─ Low confidence?
└─ Sonnet
Most requests complete on the cheaper model. Only difficult cases incur premium model costs. The downside is increased complexity and occasional double calls, which can impact latency.
Dynamic Routing
Dynamic routing is one of those ideas that sounds smarter than it usually is. The pitch is simple:
Instead of engineers deciding which model to use, let a model decide which model to use.
For example:
User Request
|
v
Router Model
|
+--> Haiku
|
+--> Sonnet
|
+--> Opus
The router attempts to predict how difficult a task is before spending money on a larger model.
Why people build it
Suppose your workload looks like this:
| Request | Actually Needs |
|---|---|
| Summarize bug report | Haiku |
| Extract acceptance criteria | Haiku |
| Generate test cases | Sonnet |
| Analyze architectural impact | Sonnet |
| Multi-system blast radius analysis | Opus |
If you send everything to the most expensive model, everything is expensive. If you use static routing:
Summarization -> Haiku
Impact Analysis -> Sonnet
You save money. But then somebody asks: What if some impact analyses are easy and some are hard?
That’s where dynamic routing enters. The challenge is that routing itself costs money and complexity. Without strong evaluation data, dynamic routing can easily become an optimization project that saves far less than expected.
For most applications, static routing captures most of the benefit with far less operational overhead.

Local Models
Running local models through Ollama or similar tooling creates a $0 tier for low-stakes tasks.
Examples include:
- Classification
- Basic extraction
- Draft generation
- Internal tooling
The tradeoff is quality consistency, especially when strict JSON output is required. For many teams, local models are a complement to routing rather than a replacement for hosted models.
Batch APIs
Both Anthropic and OpenAI offer discounted asynchronous processing. If a task doesn’t require an immediate response, batch processing can cut costs significantly.
Good candidates include:
- Evaluation suites
- Dataset labeling
- Offline analysis
- Regression testing
Interactive user-facing features usually don’t benefit.
Lever 2: Send Fewer Tokens
Most teams obsess over model selection while ignoring token efficiency. In many cases, reducing tokens delivers similar savings with less risk.
Prompt Caching
Prompt caching is one of the easiest wins available today. Large system prompts, instructions, and examples can often be cached, dramatically reducing repeated costs. If your application repeatedly sends the same context, caching should be one of the first optimizations you implement.
Reduce Output Size
This optimization is surprisingly underrated. Remember: output tokens are often the expensive side of the equation.
Instead of generating:
{
"confidence": "I am highly confident because..."
}
Generate:
{
"confidence": "high"
}
Other strategies:
- Reference IDs instead of repeating descriptions
- Use enums instead of prose
- Limit list sizes
- Lower max token limits
- Return structured data instead of explanations
A smaller response is cheaper and often easier to consume programmatically.
Context Engineering
One thing worth mentioning is that many of the techniques now grouped under context engineering are really token optimization techniques in disguise. The goal of context engineering is simple:
Give the model the information it needs, but not the information it doesn’t.
A common anti-pattern in AI applications is sending everything:
- Entire codebases
- Complete chat histories
- Every document
- Every API response
This works initially because modern models have large context windows. However, large context windows don’t make context free.
Every additional token increases:
- Cost
- Latency
- The chance the model focuses on irrelevant information
Good context engineering is about carefully selecting what enters the prompt.
Examples include:
- Retrieval (RAG)
- Context pruning
- Summarization
- Conversation memory
- Relevance ranking
- Metadata filtering
The best context isn’t the largest context. It’s the most relevant context. This is why I think of context engineering as the evolution of prompt engineering. Prompt engineering focuses on how you ask the question. Context engineering focuses on what information you provide before asking it.
Context Pruning
As applications scale, context becomes the dominant cost driver. Instead of sending everything:
Send all data
Send only:
Relevant data
This is essentially retrieval-augmented generation (RAG). However, context pruning introduces a new risk: you can accidentally remove information the model needed.
If you’re only sending 1,000–2,000 tokens today, aggressive pruning is usually premature optimization.
Prompt Compression
Many prompts contain:
- Repeated instructions
- Redundant examples
- Excessive explanations
Cleaning them up won’t transform your bill overnight, but the savings compound across millions of requests.
Chat History Management
Long conversations naturally accumulate tokens. Without limits, each new message becomes more expensive than the last.
Common approaches:
- Keep only the last N turns
- Summarize older conversations
- Store memory separately from chat history
This prevents token growth from becoming unbounded.
Lever 3: Make Fewer Calls
This is where the biggest savings often come from. A call you never make is infinitely cheaper than an optimized call.
Result Memoization
Prompt caching reduces costs. Memoization eliminates them. If the same input produces the same output, store the result.
const key = sha256(query + JSON.stringify(context));
const hit = db
.prepare('SELECT result FROM cache WHERE key = ?')
.get(key);
if (hit) {
return JSON.parse(hit.result);
}
Benefits:
- Zero model cost
- Instant response
- Reduced latency
- Lower infrastructure load
This is especially powerful for evaluation systems where users repeatedly run identical scenarios. Before investing in more sophisticated AI infrastructure, ask: Can I avoid making this call entirely?
A call you never make is always cheaper than a call you’ve optimized.
Explicit Triggers
Many AI applications accidentally generate unnecessary calls.
Examples:
- Running on every keystroke
- Re-triggering during rapid UI updates
- Double-clicking submit buttons
Simple protections help:
- Analyze only on button click
- Debounce inputs
- Disable actions while requests are in flight
These changes cost almost nothing to implement and often produce immediate savings.
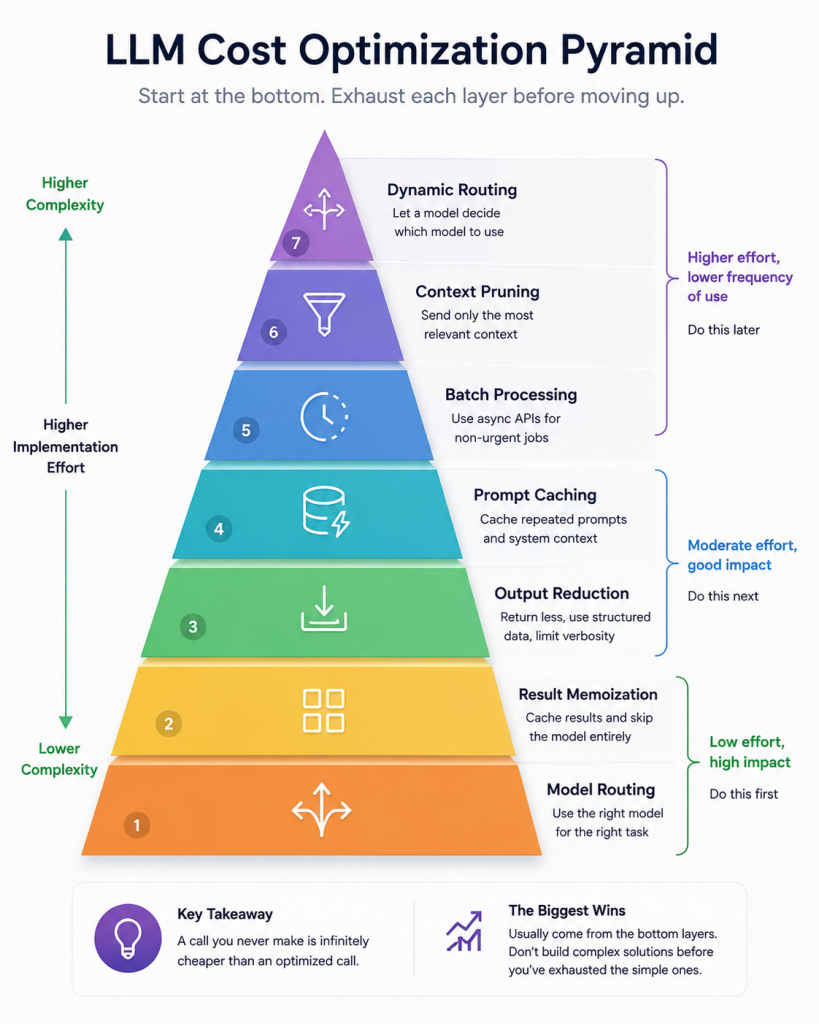
Prioritization: What I’d Do First
If you’re building a typical AI-powered application, I’d optimize in this order:
- Model routing
- Result memoization
- Prompt caching
- Output reduction
- Context engineering
- Chat history management
- Batch processing
- Context pruning
- Dynamic routing
A lot of teams jump straight to vector databases, sophisticated routing systems, agent frameworks, and complex orchestration layers. In reality, the biggest wins usually come from boring optimizations.
Interestingly, many AI infrastructure discussions today are actually context engineering discussions. RAG, vector databases, memory systems, retrieval pipelines, and summarization strategies are all attempts to answer the same question:
What is the minimum amount of information the model needs to do a good job?
Before building elaborate AI infrastructure, ask three simple questions:
- Can I use a cheaper model?
- Can I send fewer tokens?
- Can I avoid making this call entirely?
Nearly every meaningful LLM cost optimization falls into one of those buckets.