
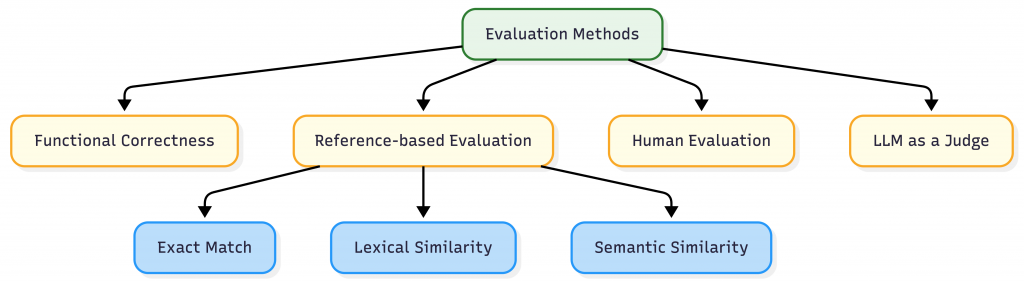
When I first started learning about LLM and AI evaluations, I struggled to put all the different evaluation methods into a single mental model. Every blog, paper, or tool seemed to focus on one technique, without clearly explaining when to use which, what each method actually measures, and how they fit together.
This post is my attempt to connect the dots.
Rather than treating evaluation methods as competing ideas, it’s much more useful to see them as layers—each answering a different question about your system.
The Core Question: What Are You Trying to Measure?
Before choosing an evaluation method, ask:
What does “good” mean for this task?
Is it:
- A single correct answer?
- Being close enough to a reference?
- Being useful or helpful to a human?
- Following instructions and reasoning correctly?
Different evaluation methods exist because no single metric can answer all of these questions.
Functional Correctness
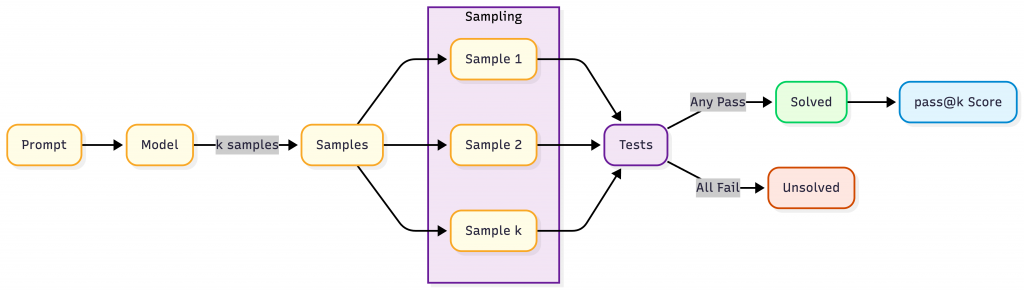
Question it answers:
Did the system do the right thing?
Functional correctness is about task success, not wording.
Examples:
- Did the SQL query return the correct rows?
- Did the code compile and pass tests?
- Did the agent successfully book the meeting?
This is the strongest form of evaluation when it’s available.
Characteristics
- Binary or near-binary (pass/fail)
- Often automated
- Domain-specific
Strengths
- High signal
- Hard to game
- Directly tied to real-world outcomes
Limitations
- Expensive or complex to implement
- Not always possible for open-ended tasks
Reference-Based Evaluation
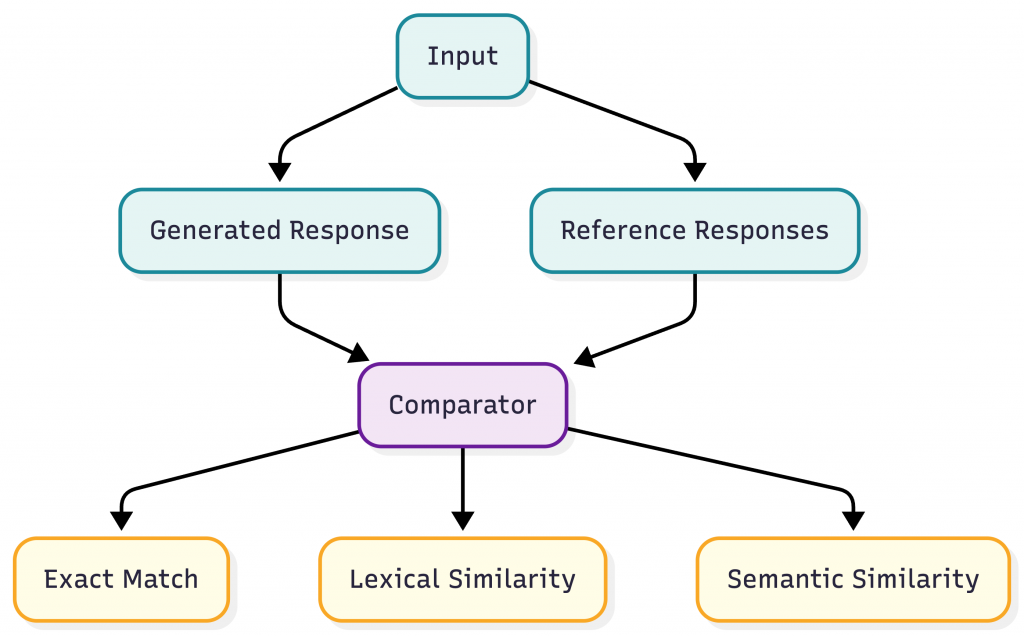
Many tasks don’t have a single “correct” output, but they do have examples of good answers. This leads to reference-based evaluation.
All methods below compare a model’s output to one or more reference answers.
Exact Match
Question it answers:
Did the output exactly match the reference?
This is the strictest reference-based method.
Examples
- Classification labels
- Yes/No answers
- Canonical IDs or tokens
Strengths
- Simple and deterministic
- Easy to automate
Limitations
- Extremely brittle
- Penalizes valid paraphrases
Exact match works best when:
- Output space is small
- Formatting matters
- There truly is only one correct answer
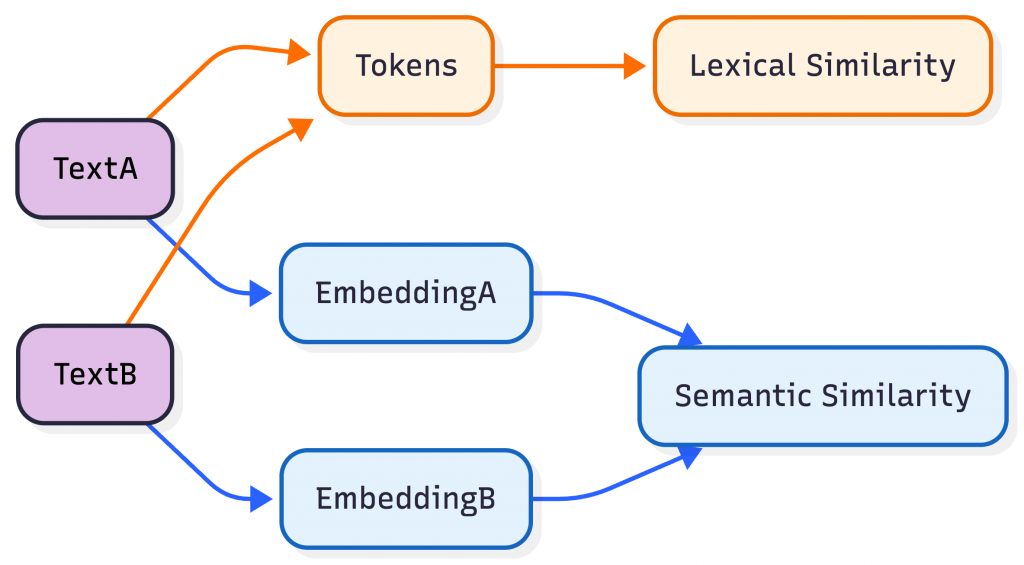
Lexical Similarity
Question it answers:
How similar is the wording to the reference?
This includes metrics like:
- BLEU
- ROUGE
- Edit distance
These metrics operate at the token or string level.
Strengths
- Cheap and fast
- Works reasonably well for structured or templated text
Limitations
- Blind to meaning
- Over-penalizes paraphrasing
- Can be gamed by copying phrasing
Lexical similarity is useful when wording consistency matters, but it should rarely be your only signal.
Semantic Similarity
Question it answers:
Does the output mean the same thing as the reference?
Semantic similarity moves beyond surface-level text and compares meaning instead.
Typically implemented using:
- Embeddings
- Cosine similarity
- Learned semantic models
Strengths
- Robust to paraphrasing
- Better aligned with human judgment
Limitations
- Sensitive to embedding quality
- Threshold selection is non-trivial
- Can miss subtle factual errors
Semantic similarity is especially useful for:
- Summarization
- QA with multiple valid phrasings
- Explanation-style outputs
Human Evaluation
Question it answers:
Is this actually good?
Human evaluation is the gold standard—when you can afford it.
Humans can judge:
- Helpfulness
- Clarity
- Tone
- Safety
- Factual accuracy
Strengths
- Highest alignment with real users
- Captures nuance no metric can
Limitations
- Expensive
- Slow
- Subjective without strong rubrics
To scale human evaluation, teams often:
- Use rubrics
- Sample strategically
- Combine with automated pre-filters
LLM as a Judge
Question it answers:
Can a model evaluate another model’s output?
LLM-as-a-Judge sits between automated metrics and human review.
Common patterns:
- Scoring answers on a rubric (0–10, pass/fail)
- Pairwise comparison (A vs B)
- Reasoned critique with justification
Strengths
- Scales far better than humans
- More semantic than lexical metrics
- Can be task-specific
Limitations
- Judge bias
- Sensitivity to prompt design
- Risk of self-preference
LLM judges work best when:
- Anchored with clear rubrics
- Validated against human judgments
- Used as one signal, not the only one
Putting It All Together
Instead of asking “Which evaluation method is best?”, ask:
Which combination of methods gives me confidence in this system?
A typical stack might look like:
- Functional correctness → Can it actually do the task?
- Exact match / lexical checks → Catch regressions
- Semantic similarity → Measure meaning preservation
- LLM-as-a-judge → Scalable qualitative assessment
- Human evaluation → Ground truth and calibration
Each layer compensates for the weaknesses of the others.
Final Thought
Evaluation isn’t about finding a perfect metric—it’s about building trust in your system.
Once I started viewing evaluation methods as complementary tools rather than competing ideas, everything started to make sense.
If you’re early in your LLM evaluation journey and feeling overwhelmed: that’s normal. Start simple, be explicit about what you’re measuring, and add complexity only when you need it.


