
AI coding tools have made writing code faster than ever. Cursor, Copilot, ChatGPT — you describe what you want, the code appears, you ship it. Velocity is up. PR volume is up. And CI failures? Also up — except debugging them hasn’t gotten any faster.
But when an AI writes a chunk of code, you don’t have the same mental model you’d have if you’d written it yourself. When CI goes red, you’re not just doing log archaeology — you’re doing it on code you didn’t fully author, in files you may have only skimmed. The gap between “8 tests failed” and “here’s what broke and why” has never been wider.
CI Sherlock is an AI agent that closes that gap. It runs as a GitHub Action after your test suite, correlates failing tests with the files changed in the PR, asks the model to reason about the root cause, and posts a plain-English summary directly on the PR — so you understand what broke before you’ve even opened the logs.
The problem with CI failures today
AI writes the code. CI tells you it’s broken. Nothing in between explains the connection.
Test runners tell you what failed. GitHub shows you what changed. But neither connects those two things — and that connection is exactly what you need when you’re reviewing a 40-file PR that an AI assistant generated in 10 minutes.
The result is the same manual process it’s always been: scan the failure, scan the diff, form a hypothesis, dig into logs. Except now you’re doing it on more PRs, with more changed files, and less personal familiarity with the code. It scales badly.
Flaky tests make this worse. If a test has a 15% failure rate across the last 20 runs, that context is invisible to anyone looking at a single CI run. You might spend time debugging something that isn’t actually broken — or asking your AI assistant to fix something that was never the problem.
What CI Sherlock does
CI Sherlock is a Python agent that plugs into any GitHub Actions workflow. After your tests run, it:
- Parses the test report (Playwright JSON for now, with a pluggable parser interface for other frameworks)
- Fetches the PR diff from GitHub — every file changed, every line
- Correlates failing tests with changed files using path matching and heuristics
- Asks Model to reason about the root cause given the failures, errors, and correlation signals
- Stores the results in SQLite for historical trend analysis
- Posts a structured summary comment on the PR
It also surfaces CI optimization signals — slow tests, missing caches, tests that could be parallelized — so the agent is useful even when your build is green.
Architecture
CI Sherlock runs entirely inside GitHub Actions. There’s no external service to maintain, no database server, no API to deploy. The only external calls are to the GitHub API and the Claude API.
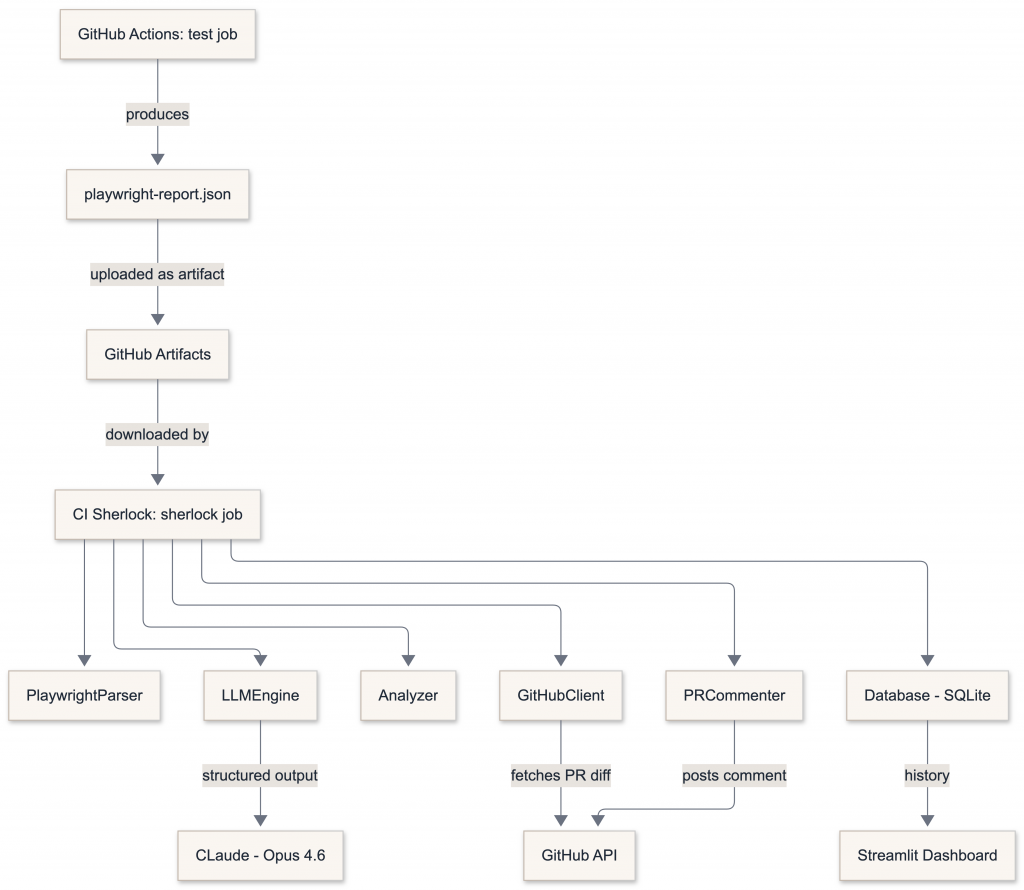
The sherlock job depends on the test job — it only runs after tests complete, whether they passed or failed. This means the agent always has access to the full test output.
Data flow
Here’s what happens step by step when a PR is opened and CI runs:
The whole flow typically adds 30–60 seconds to a CI pipeline, most of which is the LLM call.
The correlation engine
The most important piece — and the one that requires no LLM — is the correlation between failing tests and changed files.
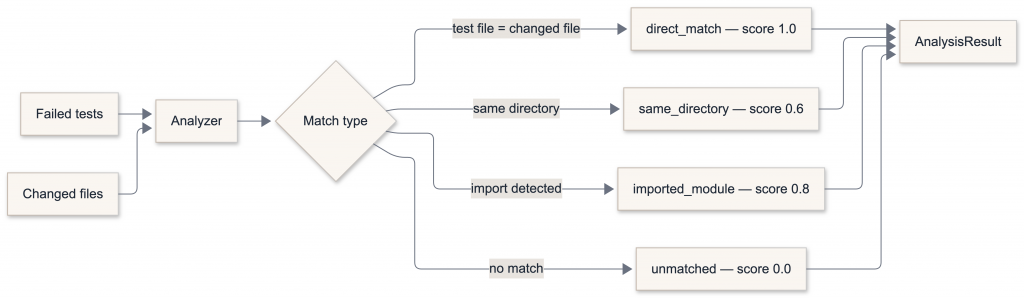
A few examples of how this plays out in practice:
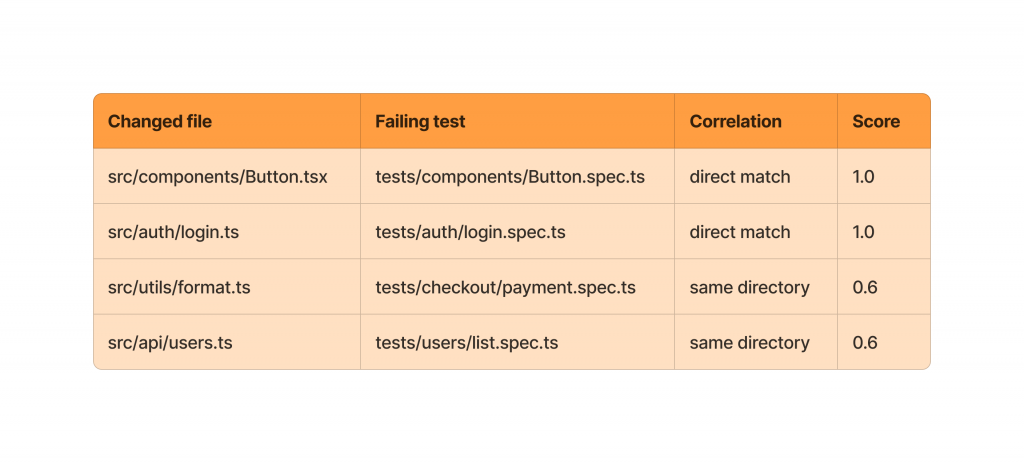
High-score correlations are passed to the LLM as strong evidence. Low-score or unmatched failures are flagged as potentially environmental or flaky.
The LLM layer
The analyzer produces a structured AnalysisResult. The LLM engine turns that into a human-readable explanation.
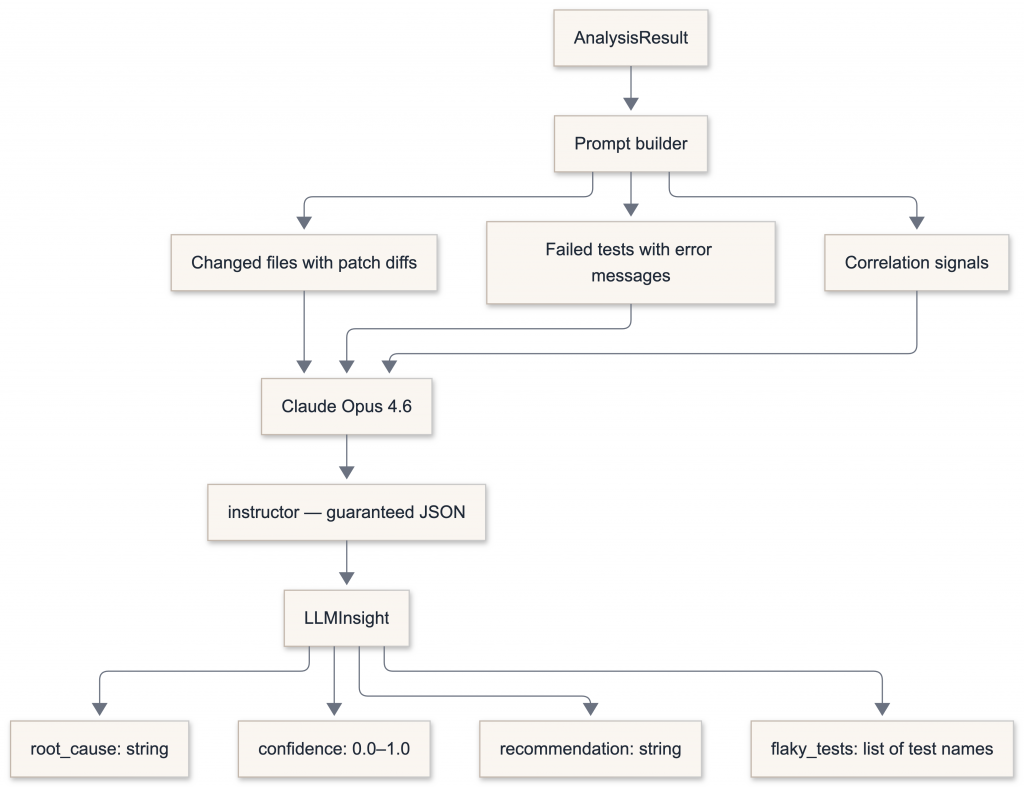
We use instructor to patch the OpenAI client, which means GPT-4o’s response is always validated against a Pydantic model. No JSON parsing errors, no partial outputs, no prompt engineering needed for output format.
class LLMInsight(BaseModel):
root_cause: str
confidence: float = Field(ge=0.0, le=1.0)
recommendation: str
flaky_tests: list[str]
insight: LLMInsight = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
response_model=LLMInsight,
)
The LLM layer is optional. If OPENAI_API_KEY is not set, the agent posts raw correlation analysis without the AI section.
Flaky test detection
Flaky tests are detected at two levels:
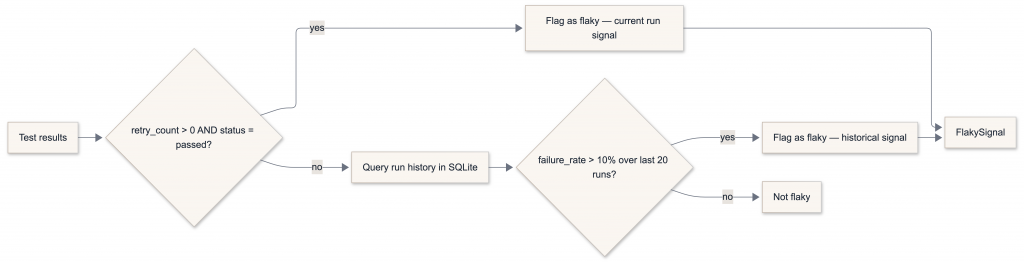
The current-run signal catches tests that retried their way to a pass. The historical signal catches tests with intermittent failures that don’t always retry — you need multiple runs in the database to see them. This is why the SQLite store matters from day one.
Persistence and the dashboard
Every run writes to SQLite. The schema is simple:
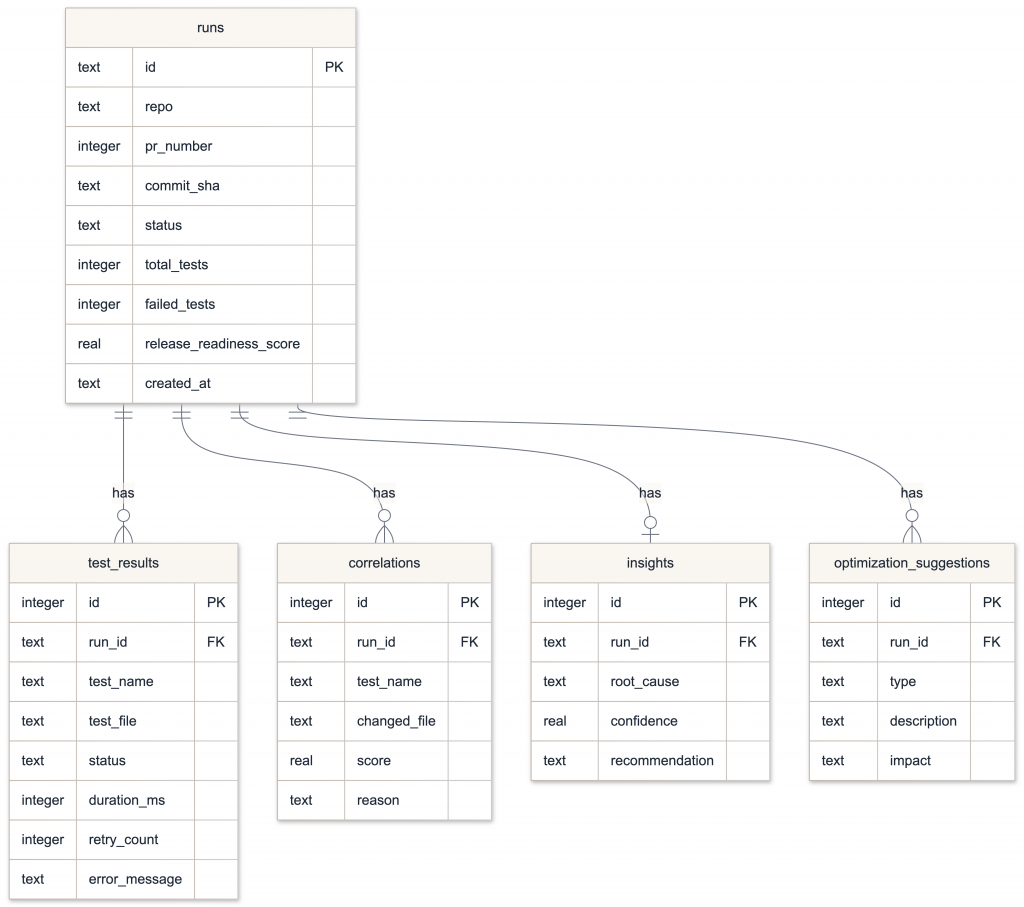
The Streamlit dashboard reads from this file and renders:
- Run timeline — pass/fail status over time
- Test failure heatmap — test × run grid, coloured by status
- Flaky leaderboard — tests ranked by failure rate
- Slowest tests — average duration chart
- Release readiness score — composite 0–100 score with factor breakdown
Run it locally after downloading the DB artifact from a CI run:
pip install git+https://github.com/slavkurochkin/ci-sherlock-agent.git
ci-sherlock dashboard --db ./history.db
The PR comment
Here’s what lands on your PR after a failed run:
## CI Sherlock Analysis
### Failures 8 tests failed
**Root cause** (82% confidence)
Recent changes to `Button.tsx` renamed the `.btn-primary` class to `.btn-default`.
Six failing tests use a selector that targets `.btn-primary` and can no longer find the element.
**Recommendation**
Update selectors in `tests/components/Button.spec.ts` and `tests/auth/login.spec.ts`
to use `.btn-default`, or add a backward-compatible alias in the component.
### Correlation
| Test | Changed file | Signal |
|---|---|---|
| `login should redirect after auth` | `src/components/Button.tsx` | direct match |
| `checkout should submit form` | `src/components/Button.tsx` | direct match |
| `signup renders submit button` | `src/components/Button.tsx` | direct match |
### Flaky tests detected
- `payment.spec.ts > should process card` — retried 2x, passed on retry (historical rate: 18%)
### CI optimization
- **Slow tests**: `checkout.spec.ts` avg 18s, `search.spec.ts` avg 15s — consider splitting
- **No test sharding detected** — pipeline could be ~40% faster with `--shard` flag
How to add it to your project
1. Configure Playwright to emit JSON
// playwright.config.ts
export default {
retries: 2,
reporter: [
["list"],
["json", { outputFile: "playwright-report.json" }]
],
use: {
trace: "on-first-retry",
}
}
2. Add the workflow
# .github/workflows/ci.yml
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm ci
- run: npx playwright test
- uses: actions/upload-artifact@v4
with:
name: playwright-report
path: playwright-report.json
if: always()
sherlock:
needs: test
runs-on: ubuntu-latest
if: always()
permissions:
pull-requests: write
contents: read
steps:
- uses: actions/checkout@v4
- uses: actions/download-artifact@v4
with:
name: playwright-report
- uses: actions/setup-python@v5
with:
python-version: '3.12'
- run: pip install git+https://github.com/slavkurochkin/ci-sherlock-agent.git --quiet
- name: Run CI Sherlock
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_REPOSITORY: ${{ github.repository }}
GITHUB_SHA: ${{ github.sha }}
SHERLOCK_PR_NUMBER: ${{ github.event.pull_request.number }}
run: ci-sherlock analyze
That’s it. No config file needed to get started.
What’s shipped
CI Sherlock was built in four phases, all now complete:

The parser is designed to be extended. Playwright is the MVP target, but the BaseParser interface means Jest, Vitest, Cypress, and pytest support can be added without touching the rest of the codebase.
What could come next:
- Additional parser targets (Jest, Vitest, pytest)
- Cache detection optimization signal
- Persistent history across CI runs via git branch storage (see
docs/HISTORY_DB_PERSISTENCE.md) - PyPI release for simpler installation
The full implementation plan, data model, and architecture docs are in the repo.
CI Sherlock is open source. The goal is a tool that makes CI failures faster to understand and easier to fix — so developers spend less time on archaeology and more time building.


