
Modern AI applications increasingly rely on Retrieval-Augmented Generation (RAG) to answer complex queries. RAG combines retrieval from a knowledge base with LLM generation for more accurate, grounded responses. But not all retrieval strategies are created equal. Let’s break down the main strategies and when to use them.
1. Baseline RAG
Flow: User Query → Embed Query → Vector Search (Top-K) → Retrieved Chunks → Build Prompt → LLM Generation → Return Answer
The baseline approach uses vector embeddings to search a knowledge base for the most relevant chunks. It’s simple, efficient, and works well for straightforward semantic queries.
Pros:
- Easy to implement
- Fast retrieval for standard queries
Cons:
- Misses paraphrased or uncommon queries
- Limited recall if the query wording is very different from documents
💡 Use case: Quick semantic search for well-structured knowledge bases.
2. Query Expansion
Flow: User Query → Generate Paraphrases → Embed Queries → Vector Search → Merge Results → Build Prompt → LLM Generation → Return Answer
Query Expansion generates 3–5 paraphrases of the original query to improve retrieval coverage. Each paraphrase is embedded and searched separately, then merged.
Pros:
- Higher recall for diverse queries
- Captures synonyms and paraphrases
Cons:
- Multiple embeddings per query → higher computational cost
- Slightly longer latency
💡 Use case: When users may phrase queries in unexpected ways or technical jargon varies.
3. HyDE (Hypothetical Document Embeddings)
Flow: User Query → Generate Hypothetical Answer → Embed Hypothetical Answer → Vector Search → Retrieved Chunks → Build Prompt → LLM Generation → Return Answer
HyDE bridges the embedding space gap between user questions and document paragraphs by first generating a hypothetical answer and embedding that. This often finds more semantically relevant chunks than embedding the query directly.
Pros:
- Better alignment with document embedding space
- Handles complex, multi-step questions
Cons:
- Requires an extra LLM call per query
- Slightly higher latency
💡 Use case: Complex reasoning tasks or long-form question answering.
4. Hybrid Search (Dense + BM25)
Flow: User Query → Dense Retrieval (Vector) + BM25 Keyword Search → Merge via RRF → Build Prompt → LLM Generation → Return Answer
Hybrid search combines dense retrieval (semantic search) with sparse keyword search (BM25). The Reciprocal Rank Fusion (RRF) algorithm merges results from both methods, providing robust results across query types.
Pros:
- Combines semantic understanding and exact keyword matching
- Performs well on rare terms or technical queries
Cons:
- Slightly more complex to implement
- More compute for dual retrieval
- retrieval
💡 Use case: When knowledge base queries include both semantic and precise keyword searches.
Choosing the Right Strategy
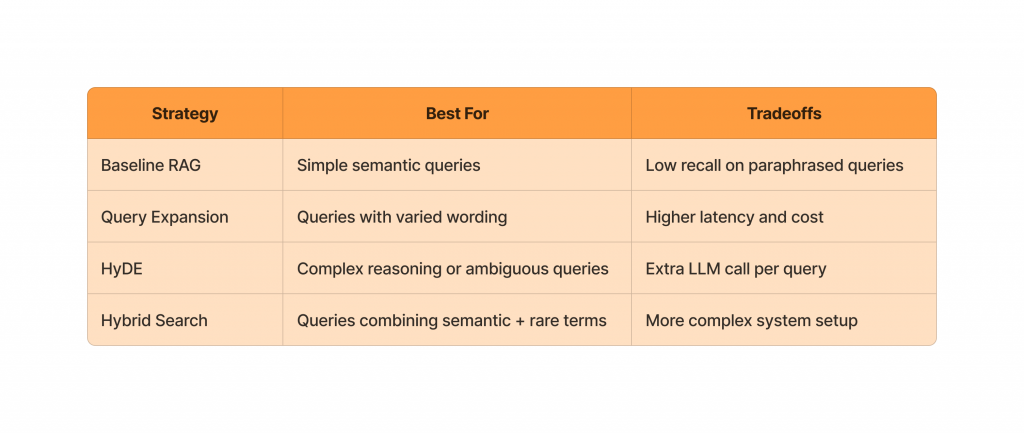
Key Takeaways
- No single strategy is perfect. Each has strengths for different query types.
- Hybrid approaches often outperform individual methods, especially for complex or technical datasets.
- Performance vs. recall is the main tradeoff: more advanced retrieval increases accuracy but also latency and cost.
- Start simple (baseline RAG), then layer in query expansion, HyDE, or hybrid search as needed.


