
Recently I had an interview conducted by an AI system. It was actually pretty interesting — and a little funny.
At one point the AI asked me:
“If you work onsite, which state will you work from?”
I answered: Georgia.
The AI replied:
“Okay, I will pass this note to George… but which state will you work from?”
So I had just answered the question — and the AI asked it again.
As someone who works in test automation, developer productivity, and AI evaluation, I immediately realized something: this wasn’t just a funny moment. It was a real-world example of how AI systems fail — and how we should test them.
This post breaks down what likely happened and how companies should actually test AI interview systems.
What Probably Happened Behind the Scenes
AI interviewers usually work as a pipeline of systems:

Somewhere in this pipeline, something failed.
Based on the response — “I’ll pass this note to George…” — my guess is one of these happened:
- Speech-to-text misheard Georgia as George
- The AI didn’t extract the state correctly
- The system didn’t store the answer
- Conversation memory failed
- The workflow treated the slot as unfilled and re-triggered the question
In AI systems, this is called a slot-filling failure.
The system should have stored something like:
state = "Georgia"
But if that value is missing, the AI asks the question again.
The Part Many People Don’t Realize
AI interviews are not just an LLM problem.
They involve multiple systems working together:
- Speech recognition
- Language understanding and entity extraction (handled by the LLM in modern systems)
- Conversation memory
- Workflow orchestration
- Voice synthesis
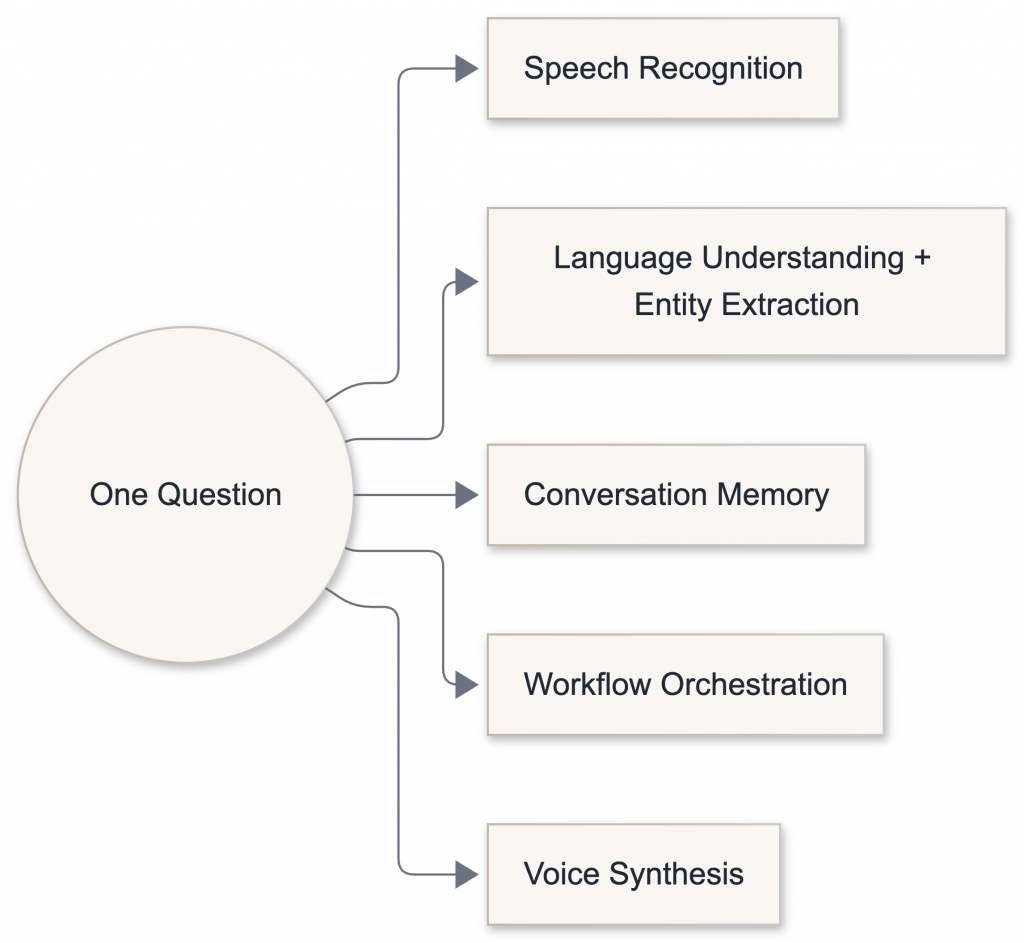
When any of these fail, you get moments like mine.
Testing Speech-to-Text (Where the Bug Might Have Happened)
If the interview uses voice, the system first converts audio into text — meaning the system might not receive what you actually said. That single transcription step can corrupt everything downstream.
One likely scenario — STT mishearing the answer:
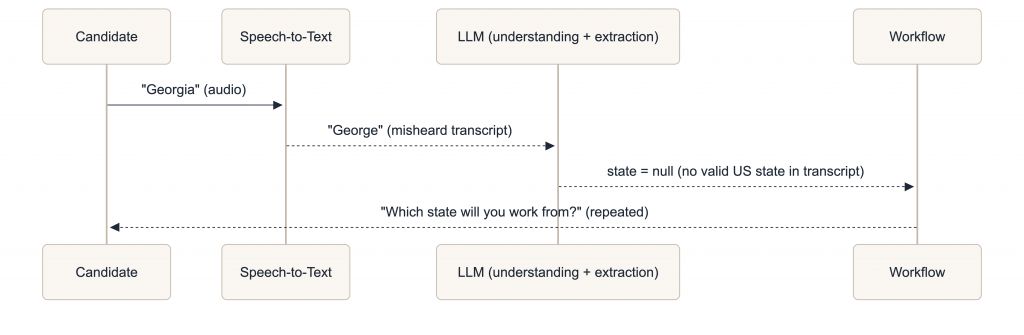
This is exactly the type of scenario companies should test.
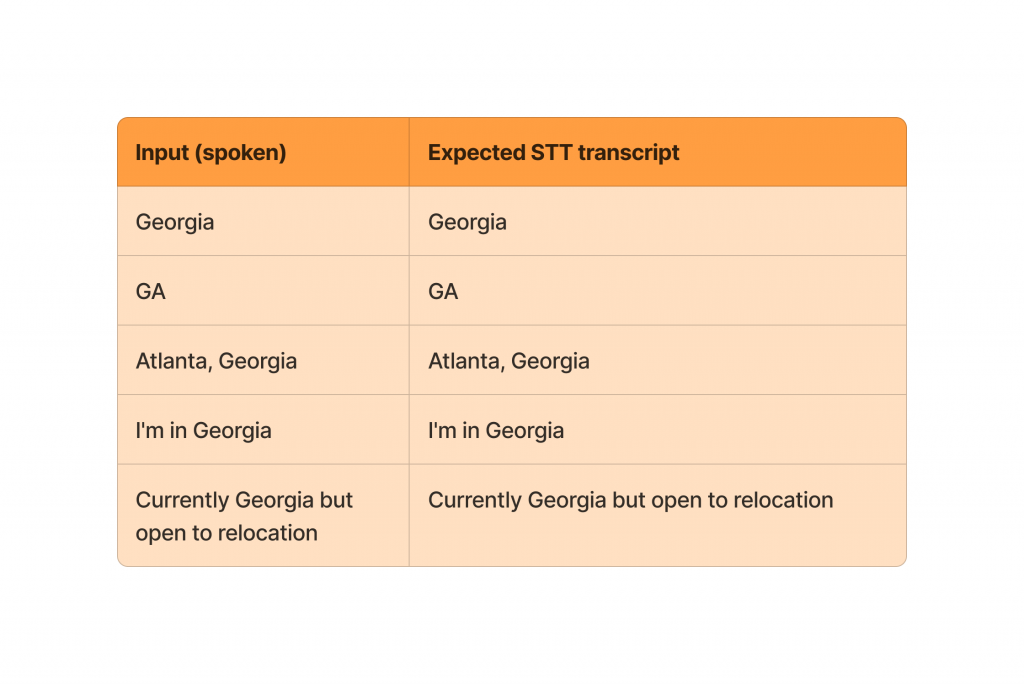
STT test dataset — does the system transcribe the audio correctly?
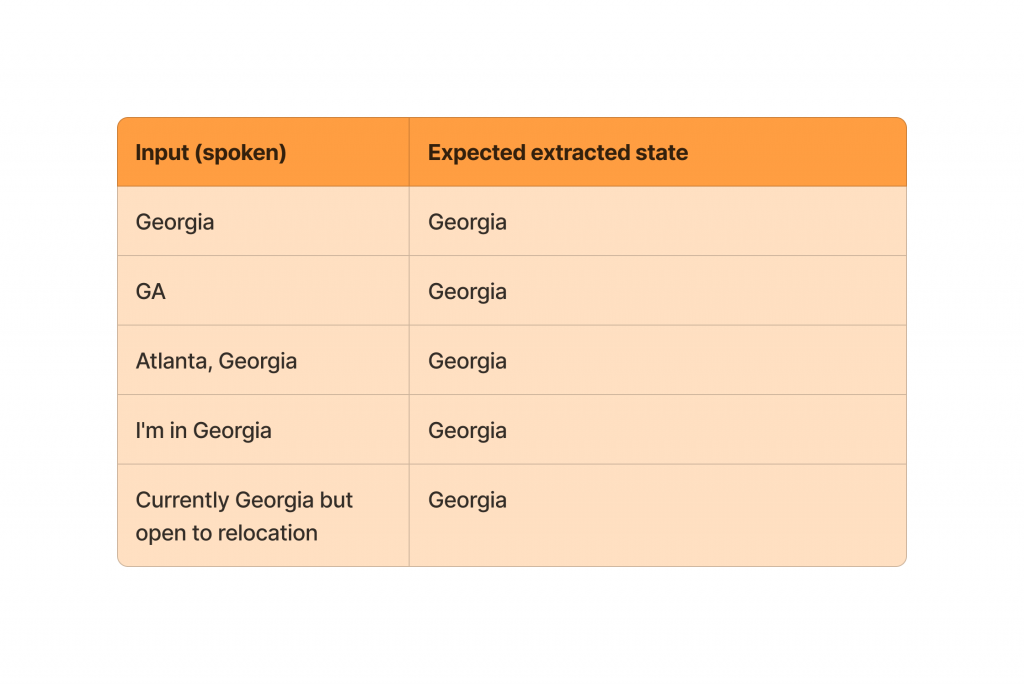
Full-pipeline test dataset — does the correct state reach the workflow?
Metrics teams should track:
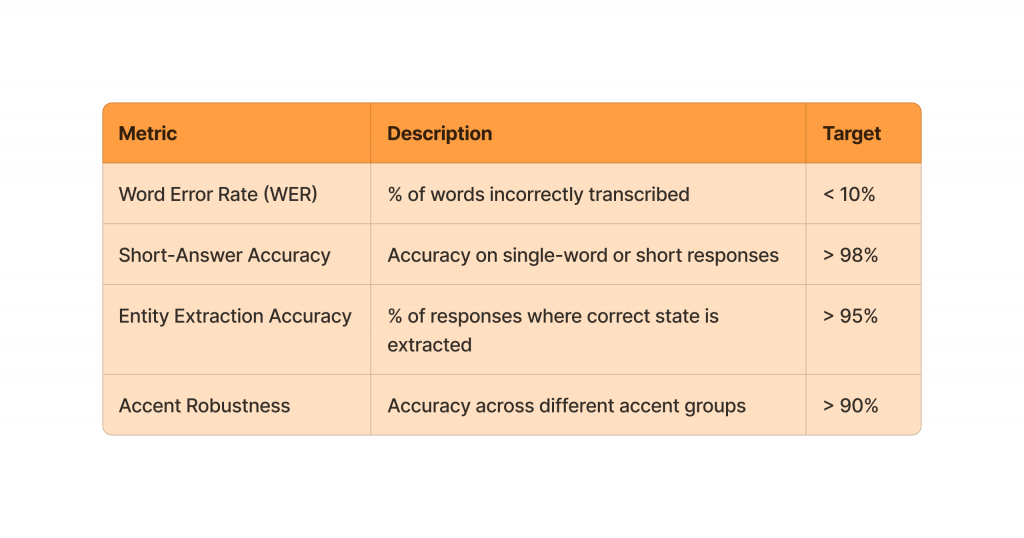
Short answers like state names, numbers, and yes/no are actually some of the hardest cases for speech recognition systems. Clean studio audio can achieve WER under 5%, but real interview conditions — browser microphones, background noise, varied accents — typically push that to 8–12%.
Testing the Conversation Logic (Where Many AI Systems Break)
AI interviewers are multi-step workflows. What made my experience so memorable was how seamless the failure looked from the outside — it just asked the question again, politely, as if nothing had happened. That is actually harder to catch than an outright error.
What happened in my interview:
AI: Which state will you work from?
User: Georgia
AI: Which state will you work from? ← FAILURE
That should immediately trigger a test failure. This type of test is called multi-turn conversation testing.
Here is the decision logic that should have run:

Basic variations (abbreviations, sentences, tenses) are covered in the full-pipeline test dataset in the STT section above. The real stress test is edge cases — inputs where a naive extraction would fail or produce the wrong result:
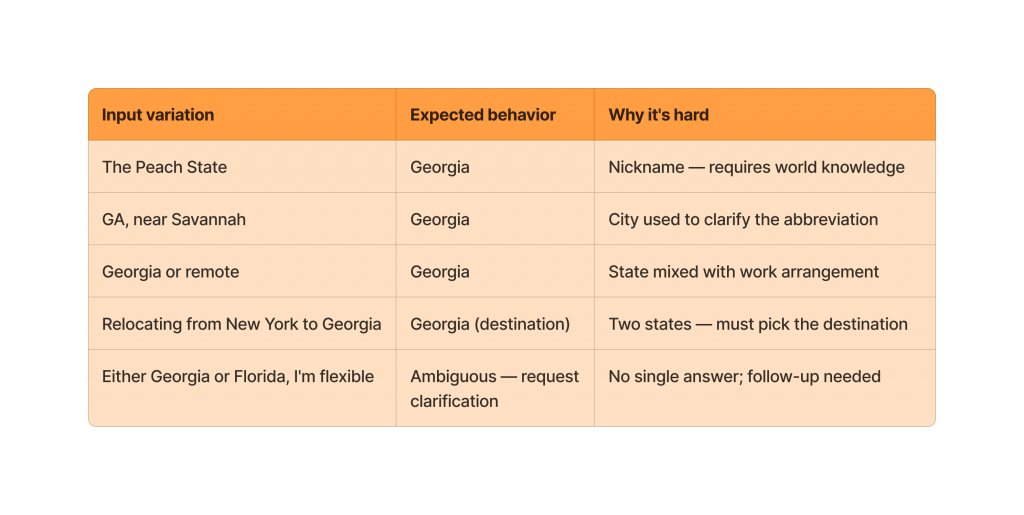
The last two cases are particularly important. If the system blindly extracts the first state it sees, “Relocating from New York to Georgia” produces the wrong answer. If it forces a single value from “Georgia or Florida,” it silently drops valid ambiguity. Both are real failure modes worth testing explicitly.
Testing Text-to-Speech (What the Candidate Hears)
Text-to-speech is another piece that affects the candidate experience.
Even if the AI understands you correctly, problems can happen here:
- Long response delays
- Robotic or unnatural voice
- Incorrect word emphasis
- Reading an unresolved variable name instead of its value
- Repeating sentences
For AI interviews, latency is critical — if the AI pauses too long, candidates think the system is broken.
TTS Test Checklist:
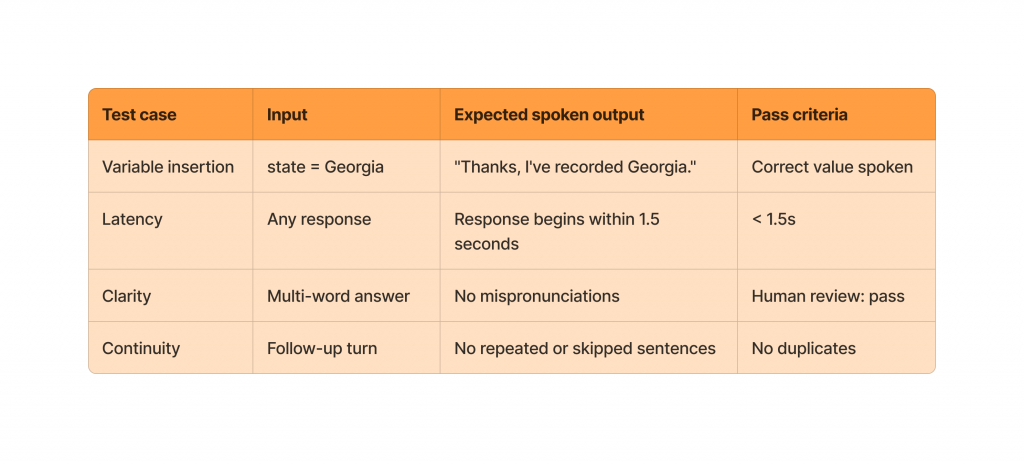
The Most Important Test: End-to-End
The real test is the entire system working together.
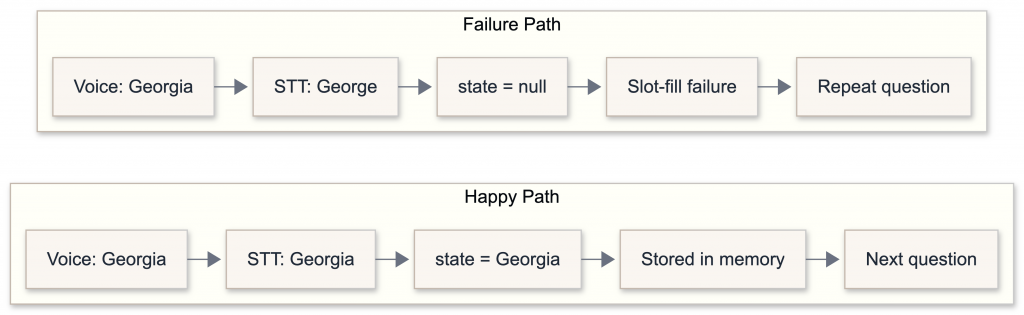
This is why end-to-end testing is critical for AI systems.
Turning Real Failures Into Tests
This experience should become a permanent test case.
Good AI teams build datasets from real interactions like this. Every strange conversation becomes a test. I filed mine mentally the moment it happened — and now it lives here.
And to be fair the team behind AI did ask provide a feedback on how AI assistant did.
Final Thought
Being interviewed by an AI was actually fascinating — not because it was perfect, but because it revealed how these systems really behave in the wild.
The irony is that this failure happened to someone who tests AI systems for a living. But that’s the point — these failures don’t announce themselves. They look like a polite, functioning system asking a reasonable follow-up question.
The only way to catch them is to build test suites that treat every real interaction as a data point. Every confusing AI moment is essentially: a new test case waiting to be written.


