Most AI agent failures don’t come from “bad prompts.” They come from treating agents like static functions instead of dynamic systems.
Once an agent can:
plan
call tools
observe results
maintain state
retry or recover
…it is no longer a prompt. It is a closed-loop control system.
Real-world AI applications are complex. Each application might consist of many components, and a task might be completed after many turns. Evaluation can happen at different levels: per task, per turn, and per intermediate output.
This post outlines a systems-first approach to evaluating AI agents — from single-turn reasoning tests to multi-turn system reliability.
What an AI Agent Actually Is (The Loop)
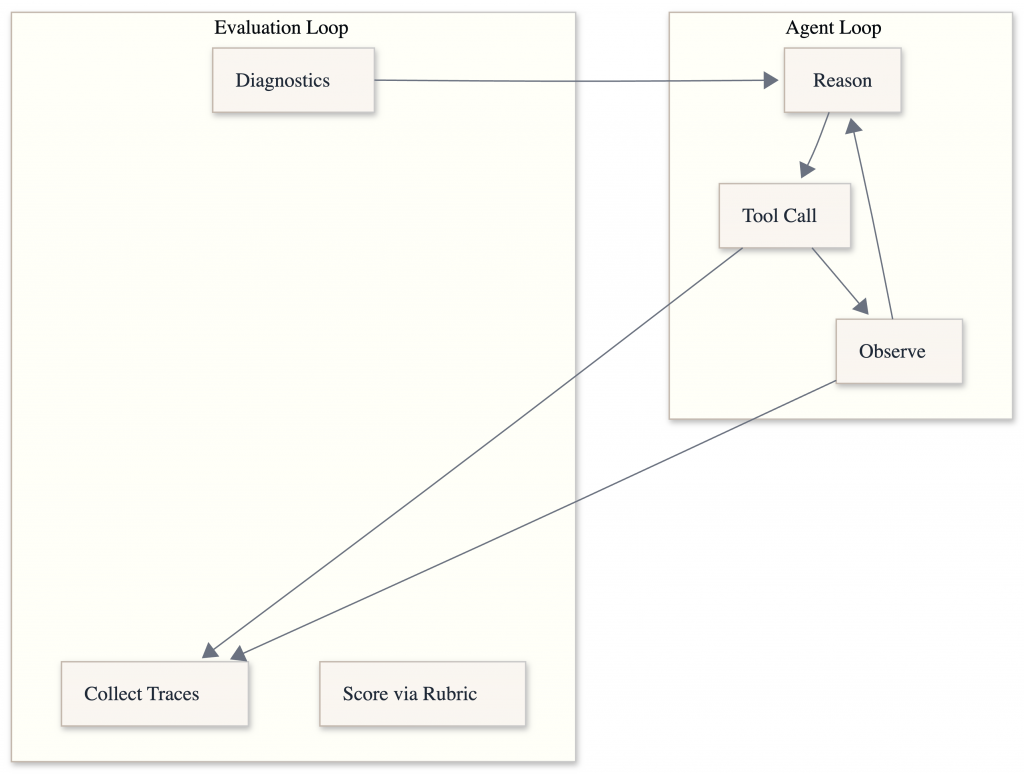
An AI agent is not a LLM response. It is a loop.
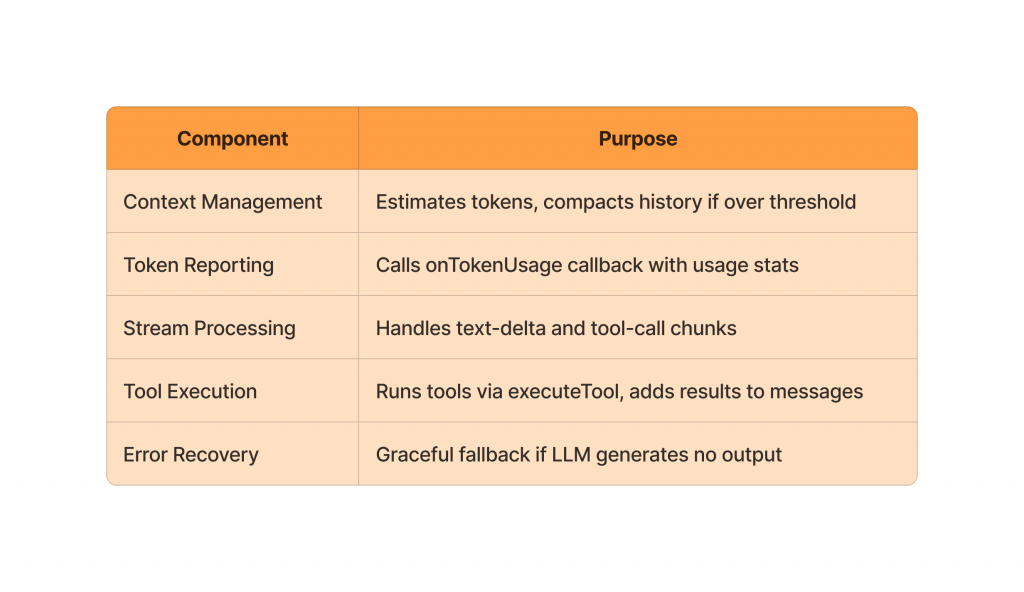
An AI agent is best understood as a loop rather than a single response: it observes the current state or input, reasons about what to do next, acts by calling a tool, API, or producing an output, and then evaluates the result before repeating the cycle if needed. In single-turn systems, this loop runs once and stops, making evaluation mostly about response correctness and quality; in task-based (multi-turn) agents, the loop continues across multiple steps, where state management, decision quality, tool usage, and recovery from errors all matter. This looping nature is what makes agent evaluation fundamentally different from evaluating a one-off model answer—you’re assessing not just what the model says, but how it iterates toward a goal.
Typical Agent Loop
This loop is why traditional prompt testing breaks:
Reasoning affects actions
Actions affect the state
State affects future reasoning
Evaluation must observe the loop, not just the output.
Single-Turn vs Task-Based (Multi-Turn) Evaluation
Agent evaluation has two fundamentally different layers.
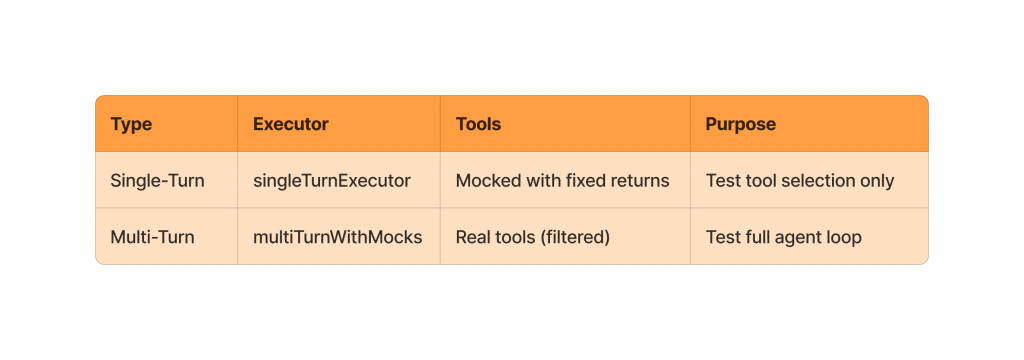
Single-turn evaluations evaluate just one pass of an agent, examining metrics for a single interaction without completing a full task. Full run evals evaluate the entire system from start to finish, including all steps and tool calls needed to complete a task. This is analogous to unit testing versus end-to-end testing.
Turn-based evaluation evaluates the quality of each output. Task-based evaluation evaluates whether a system completes a task.
Single-Turn Evaluation
Single-turn evaluation focuses on assessing an AI model’s response to a single input without any memory of prior context or follow-up actions. The model receives a prompt, produces one output, and the interaction ends, which makes evaluation relatively straightforward and repeatable. Common criteria include correctness, relevance, completeness, style, and safety, often measured through exact match, similarity metrics, or human judgment. Because there is no state or decision-making across steps, single-turn evaluation is primarily about output quality, not the process used to generate it.
Question:Can the agent think correctly?
Tools are mocked
No real execution
Deterministic and fast
Equivalent to unit tests
But why do you mock tools instead of letting them run? Mocking tools in single-turn evaluation isolate the model’s reasoning and decision-making from external system variability. Real tools can be slow, flaky, rate-limited, or return changing data, which introduces noise and makes results hard to reproduce. By using mock tools with deterministic responses, you can consistently evaluate whether the model knows when and how to use a tool, without conflating model quality with infrastructure issues. This keeps single-turn evaluations focused on model behavior, not the reliability of downstream systems.
Catches:
wrong tool selection
hallucinations
bad planning
unsafe actions
Single-Turn Eval Rubric
Dimension
What You’re Testing
Intent understanding
Did it understand the task?
Plan quality
Are steps ordered logically?
Tool selection
Correct API for the action
Argument validity
Selectors & params are real
Reasoning trace
Explains why each step exists
Safety constraints
Avoids destructive ops
Determinism
Stable output across runs
Task-Based (Multi-Turn) Evaluation
Task-based (multi-turn) evaluation measures how well an AI system performs across a sequence of steps while working toward a defined goal. Instead of judging a single response, you evaluate the agent’s ability to maintain state, choose appropriate actions, use tools correctly, adapt to new information, and recover from mistakes over time. Success is determined by whether the task is completed efficiently and correctly, not just by the quality of individual turns. This makes multi-turn evaluation closer to real-world usage, where reasoning, planning, and iteration matter as much as the outcome.
Because users care most about task completion, task-based evaluation is especially important. Its main challenge lies in clearly defining where one task ends and another begins.
An important consideration is whether the application completed the task and how many interaction turns were required. Solving a task in a couple of turns is meaningfully different from needing dozens.
Question:Can the system survive reality?
Real tools
Real failures
Real state
Equivalent to integration + E2E tests
Catches:
state loss
infinite loops
flaky recovery
latency explosions
partial success
Multi-Turn Eval Rubric
Category
Why It Matters
Task completion
Did the job finish?
Error detection
Did it notice failures?
Recovery quality
Did it adapt intelligently?
State management
Did it remember context?
Loop control
Did it terminate correctly?
Latency
Is it usable in prod?
Observability
Can we debug it?
Key insight:
How an agent fails matters more than whether it fails.
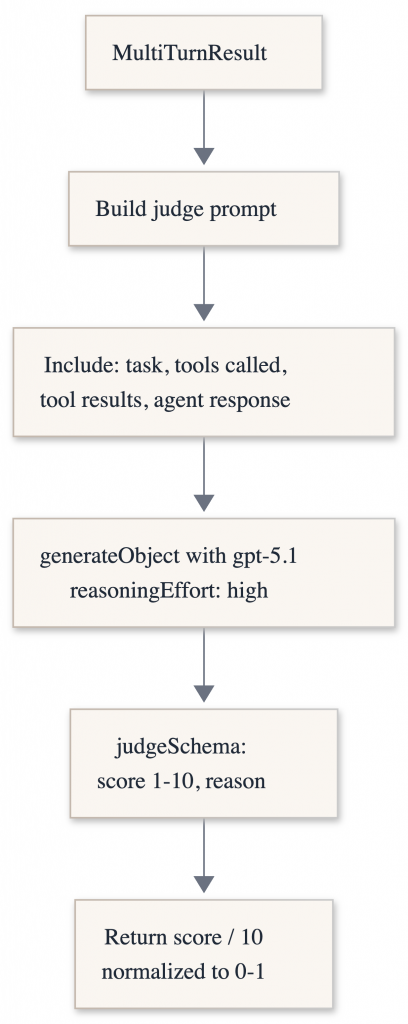
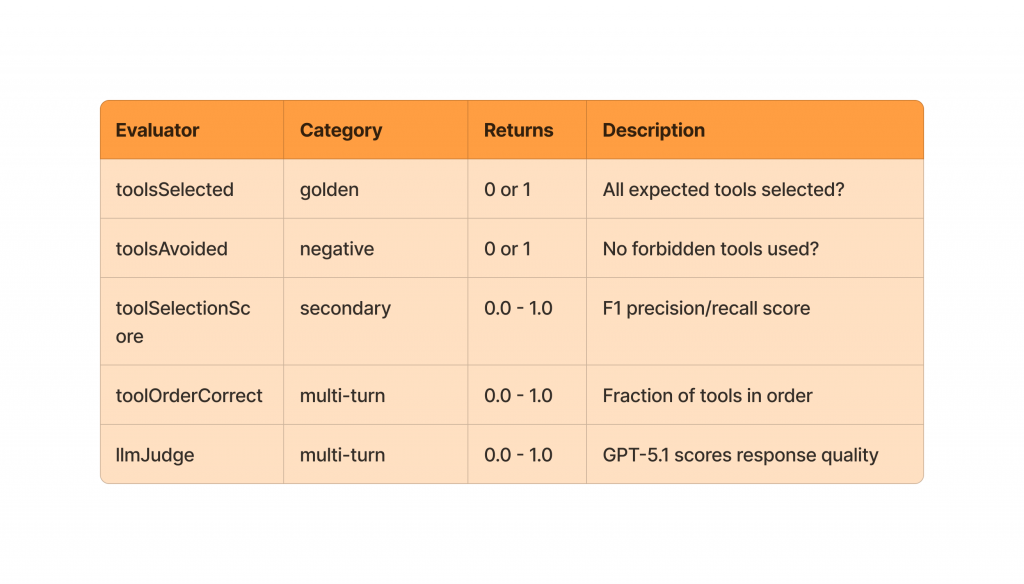
Both types of evaluations need a way to determine whether a system passed or failed, remained unchanged, regressed, or improved. An evaluator serves as an assertion or test that converts qualitative outputs into quantitative scores by comparing the actual output to the expected outcome and measuring how closely they align.
Evaluation should not steer the agent directly. It should observe, score, and diagnose.
The evaluator tunes the system between runs, not during execution.
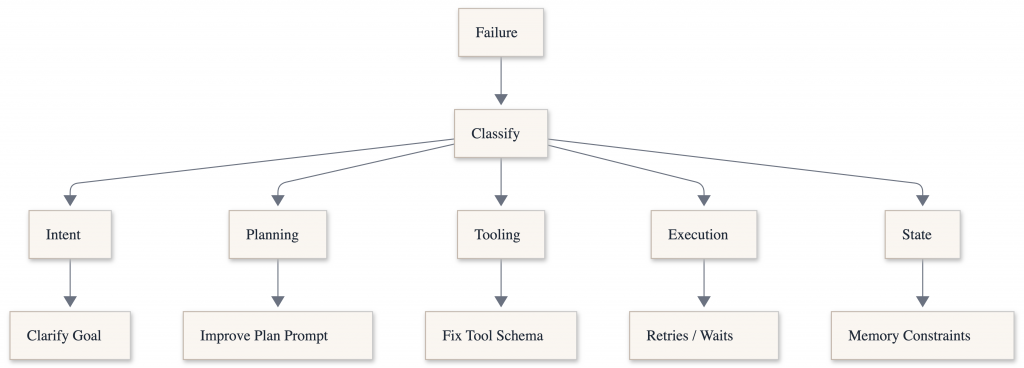
Failure classification
Failure classification is the process of categorizing why an AI system failed, rather than just noting that it failed. Instead of a single “wrong answer” label, failures are categorized into types, including reasoning errors, tool misuse, hallucinations, state loss, instruction misinterpretation, or poor recovery behavior. This is especially important for task-based agents, where an early mistake can have a cascading effect across multiple steps. Clear failure classification turns evaluations into actionable signals, helping teams understand what to fix and track whether changes actually improve agent behavior over time.
This turns debugging from guesswork into engineering.
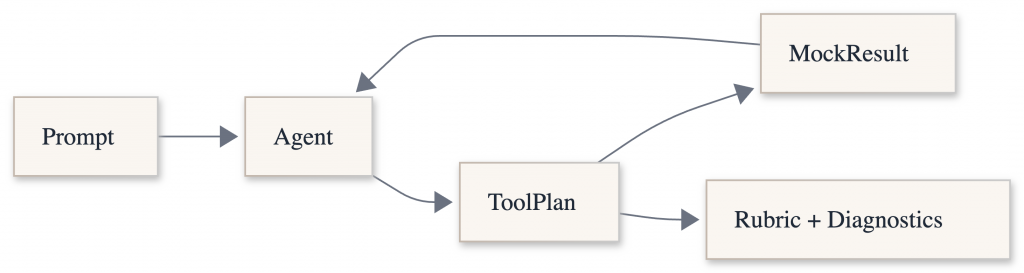
Evaluation Flow
Load dataset from JSON (prompt + expected results)
Run executor (single-turn or multi-turn)
Apply evaluators based on the category
Classify failures and Report scores
AI agents are not intelligent scripts. They are feedback systems operating under uncertainty.