
Promptfoo is excellent at what it does: comparing prompts, running assertions, and catching regressions in CI. But if you’re building a RAG pipeline, Promptfoo’s built-in assertions — contains, llm-rubric, icontains — test the output. They can’t tell you whether your retrieval is pulling the right documents, whether the model is faithful to the context it received, or whether your chunks have sufficient coverage of the ground truth.
That’s where RAGAS comes in. It provides four metrics purpose-built for RAG evaluation: faithfulness, answer relevancy, context precision, and context recall. Together, Promptfoo and RAGAS cover the full surface area of a RAG system.
This post shows how to wire them together.
What Promptfoo Can’t Measure
Consider a typical Promptfoo config for a RAG pipeline:
tests:
- vars:
question: "What are the four DORA metrics?"
assert:
- type: contains
value: "deployment frequency"
- type: contains
value: "lead time"
- type: llm-rubric
value: "The answer should discuss all four DORA metrics"
This checks whether the output contains the right content. But it can’t answer:
- Was the answer faithful to the retrieved context? The model might produce a correct answer from parametric knowledge while ignoring the retrieved chunks entirely. The output looks right, but your retrieval is broken.
- Did retrieval surface the right documents? The model might answer correctly despite getting irrelevant chunks — or fail because the right chunk was ranked 6th out of 5.
- How precise is the retrieved context? Are all returned chunks relevant, or is the model sifting through noise?
These are retrieval problems, not prompt problems. You need different tools to measure them.
RAGAS in 60 Seconds
RAGAS evaluates four dimensions of RAG quality:
| Metric | Measures | Needs Ground Truth? |
|---|---|---|
| Faithfulness | Can every claim in the answer be traced back to the retrieved context? | No |
| Answer Relevancy | Does the answer actually address the question? | No |
| Context Precision | Are the retrieved chunks relevant to the question? Are relevant ones ranked higher? | Yes |
| Context Recall | Does the retrieved context cover all the information in the ground truth answer? | Yes |
The first two evaluate generation quality. The last two evaluate retrieval quality. You need all four to understand where your RAG pipeline is failing.
RAGAS uses an LLM as a judge internally — it decomposes answers into claims and checks each one against the context. This makes it more expensive than string matching but far more meaningful.
Architecture: How the Two Tools Fit Together
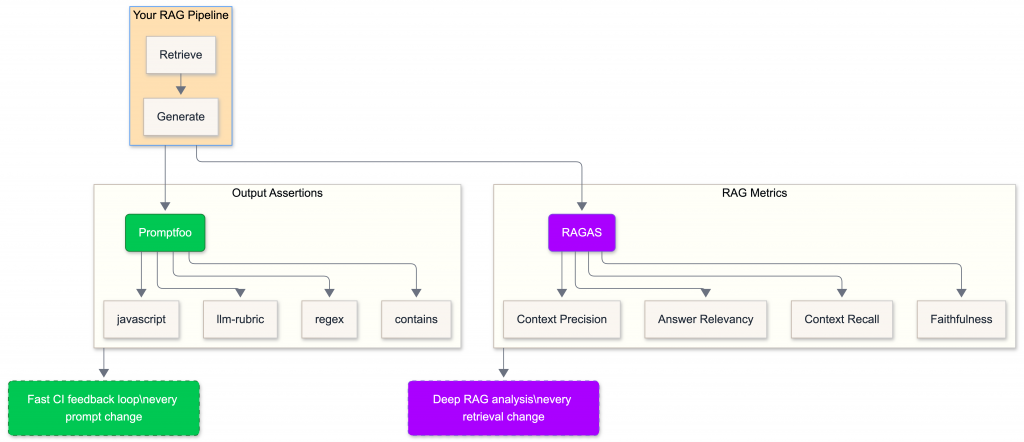
Promptfoo gives you a fast feedback loop: run it on every prompt change, in CI, comparing model A vs model B. RAGAS gives you deep analysis: run it when you change your chunking strategy, embedding model, or retrieval parameters.
The key insight is that the same RAG pipeline feeds both tools. You just need to wire it correctly.
Wiring Your RAG Pipeline as a Promptfoo Provider
Promptfoo’s custom Python provider is how you bridge the gap. Instead of testing a raw LLM, you test your entire RAG pipeline — retrieval and generation together.
Here’s the provider:
# promptfoo_provider.py
import sys
sys.path.append(".")
from rag.query import ask
def call_api(prompt: str, options: dict, context: dict) -> dict:
"""Promptfoo custom provider that runs the full RAG pipeline."""
question = prompt.strip()
try:
result = ask(question, k=5)
return {
"output": result["answer"],
"metadata": {
"contexts": [c["text"][:200] for c in result["context_chunks"]],
"sources": [c["source"] for c in result["context_chunks"]],
"tokens": result["tokens"],
},
}
except Exception as e:
return {"error": str(e)}
The call_api function is the contract Promptfoo expects. It receives the prompt (your test question), calls your RAG pipeline, and returns the output plus metadata. The metadata is surfaced in the Promptfoo UI — useful for debugging which sources were retrieved.
Your Promptfoo config points to this provider:
description: "RAG Pipeline Evaluation"
prompts:
- "{{question}}"
providers:
- id: "python:promptfoo_provider.py"
label: "RAG Pipeline (k=5)"
tests:
- vars:
question: "What are the four DORA metrics?"
assert:
- type: contains
value: "deployment frequency"
- type: llm-rubric
value: "The answer should discuss all four DORA metrics"
# Hallucination trap — made-up tool name
- vars:
question: "How do I configure KubeFluxCD for GitOps workflows?"
assert:
- type: llm-rubric
value: "KubeFluxCD is not a real tool. The response should indicate it doesn't have information about this tool."
# Out-of-scope question
- vars:
question: "What is the capital of France?"
assert:
- type: llm-rubric
Run it the same way you’d run any Promptfoo eval:
promptfoo eval -c promptfooconfig_rag.yaml
promptfoo view
ou can create multiple providers with different parameters — different k values, different system prompts, strict vs. flexible context handling — and compare them side by side. That’s the power of Promptfoo’s provider model applied to RAG.
Running RAGAS Alongside Promptfoo
RAGAS needs a dataset with four fields: question, answer, contexts, and ground_truth. You generate this by running your RAG pipeline and pairing the results with human-written ground truth answers.
Here’s the evaluation script. Note the use of llm_factory — this is the current RAGAS 0.4.x API. If you find examples using LangchainLLMWrapper, those are deprecated.
# eval/run_ragas.py
import json
from openai import OpenAI
from datasets import Dataset
from ragas import evaluate
from ragas.llms import llm_factory
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_precision,
context_recall,
)
class EmbeddingsAdapter:
"""Bridge between OpenAI embeddings and RAGAS's expected interface."""
def __init__(self, client, model="text-embedding-3-small"):
self.client = client
self.model = model
def embed_query(self, text: str) -> list[float]:
response = self.client.embeddings.create(input=[text], model=self.model)
return response.data[0].embedding
def embed_documents(self, texts: list[str]) -> list[list[float]]:
response = self.client.embeddings.create(input=texts, model=self.model)
return [d.embedding for d in response.data]
def run_evaluation(eval_dataset_path: str):
with open(eval_dataset_path) as f:
data = json.load(f)
dataset = Dataset.from_dict({
"question": [d["question"] for d in data],
"answer": [d["answer"] for d in data],
"contexts": [d["contexts"] for d in data],
"ground_truth": [d["ground_truth"] for d in data],
})
openai_client = OpenAI()
llm = llm_factory("gpt-4o-mini", client=openai_client)
emb = EmbeddingsAdapter(openai_client)
results = evaluate(
dataset=dataset,
metrics=[faithfulness, answer_relevancy, context_precision, context_recall],
llm=llm,
embeddings=emb,
)
df = results.to_pandas()
for name in ["faithfulness", "answer_relevancy", "context_precision", "context_recall"]:
if name in df.columns:
print(f"{name:<25} {df[name].dropna().mean():.4f}")
df.to_csv("eval/ragas_results.csv", index=False)
if __name__ == "__main__":
run_evaluation("eval/eval_dataset.json")
The EmbeddingsAdapter class is necessary because RAGAS’s legacy metrics expect embed_query/embed_documents methods, and the adapter bridges that to the OpenAI client directly.
Your eval dataset is a JSON file:
[
{
"question": "What are the four DORA metrics?",
"answer": "The four DORA metrics are...",
"contexts": ["Chunk 1 text...", "Chunk 2 text..."],
"ground_truth": "The four DORA metrics are deployment frequency, lead time for changes, change failure rate, and time to restore service."
}
]
The answer and contexts fields come from running your RAG pipeline. The ground_truth field is what you write by hand — it’s the “right” answer that context recall is measured against.
When to Use Which
Don’t run both tools on every change. Use the right tool for the change you’re making:
| What changed | Run | Why |
|---|---|---|
| Prompt wording | Promptfoo | Fast comparison, assertions catch regressions |
| Model swap (GPT-4o → Claude) | Promptfoo | Side-by-side output comparison |
| Chunking strategy | RAGAS | Context precision/recall reveal retrieval quality |
| Embedding model | RAGAS | Retrieval metrics show if better embeddings help |
k parameter (top-k results) | Both | Promptfoo for output quality, RAGAS for retrieval precision |
| New knowledge base documents | Both | RAGAS for retrieval coverage, Promptfoo for output correctness |
Promptfoo in CI, RAGAS on demand. Promptfoo runs fast enough for every PR. RAGAS makes dozens of LLM-as-judge calls per question — run it when you change the retrieval layer, not on every commit.
Gotchas and Lessons Learned
Python version compatibility. RAGAS and its dependencies (especially vector databases like ChromaDB) can be picky about Python versions. Python 3.11 or 3.12 is the safe bet. If you’re on 3.14, expect broken Pydantic v1 dependencies. Consider FAISS (faiss-cpu) as a lightweight alternative to ChromaDB — it has no server dependency and fewer compatibility issues.
RAGAS API churn. The RAGAS API has changed significantly across versions. In 0.4.x, use llm_factory for LLM setup — not LangchainLLMWrapper, which older tutorials reference. The ragas.metrics.collections metrics use a different base class than ragas.metrics and aren’t compatible with evaluate() — stick with the top-level imports from ragas.metrics.
LLM-as-judge cost. RAGAS decomposes each answer into individual claims and checks each one against the context. For 20 questions across 4 metrics, expect ~80 LLM calls. At GPT-4o-mini prices this is cents, but with GPT-4o it adds up. Always use a cheaper model for RAGAS evaluation.
Cost assertions don’t work with custom providers. Promptfoo’s cost assertion type requires the provider to return cost data. Custom Python providers don’t — only the built-in OpenAI/Anthropic providers do. If you add a cost assertion to a custom provider config, it will always fail. Remove it; track cost through your provider’s metadata instead.
Ground truth is the bottleneck. RAGAS’s context precision and context recall metrics need ground truth answers. Writing these by hand is tedious but essential — the quality of your RAGAS evaluation is only as good as your ground truth dataset. Start with 15-20 high-quality Q&A pairs rather than 100 sloppy ones.
Final Thought
Promptfoo treats prompts like code — version-controlled, tested, compared. RAGAS treats retrieval like infrastructure — measured, benchmarked, monitored.
If you’re building a RAG system, you need both. Use Promptfoo for fast iteration on prompts and output quality. Use RAGAS to understand whether your retrieval pipeline is actually pulling the right context and whether your model is faithful to it.
The wiring is straightforward: your RAG pipeline is a Promptfoo custom provider and a RAGAS data source. Same pipeline, two lenses, full coverage.


